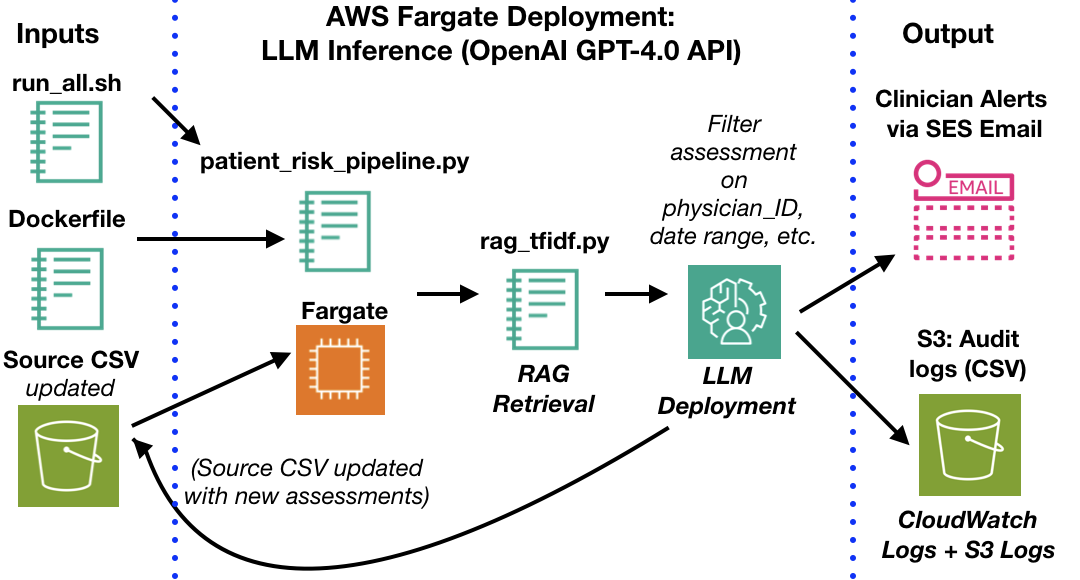
An AWS-deployed, agentic LLM pipeline that scans free-text clinical notes,
flags patients at elevated risk, and sends structured, review-ready email summaries to clinicians —
all while keeping clinicians fully in the loop.
Clinician alerts via SES email, with structured outputs and full audit logs persisted in S3
Using OpenAI GPT models deployed on AWS infrastructure, this project analyzes unstructured clinical notes to identify high-risk patients and generate actionable insights for care teams.
This tool is designed to assist clinicians, not replace them — all flagged patients are intended to be reviewed manually by a qualified clinician before any action is taken.
🌐 Workflow Overview
The pipeline automatically processes incoming patient notes, surfaces those at greatest risk, and delivers summarized insights to clinicians, helping save time and prioritize follow-up.
On a scheduled basis (e.g., weekly), the application automatically scans patient notes
from a configurable lookback window.
The application can also be run on demand from the command line. Customized timeframes, clinician ID(s), and custom risk-threshold levels may be specified.
This application is designed to augment, not replace, the clinician. It automates a highly time-consuming yet crucial aspect of a clinician's role — note review — for a fraction of the time and cost. This frees clinicians from time spent in review, enabling them to reallocate this time to direct contact with their patients.
Agentic AI Clinical Risk Pipeline - Architecture Overview
📚 Retrieval-Augmented Clinical Reasoning (RAG)
To improve factual grounding, consistency, and explainability, the pipeline incorporates
retrieval-augmented generation (RAG) as a first-class component of the
clinical risk assessment workflow.
Prior to risk scoring and summarization, each patient note is compared against a curated
clinical knowledge base focused on common high-risk medical scenarios and red-flag patterns.
The most semantically relevant reference snippets are retrieved and injected into the LLM
context, where they inform downstream reasoning and summarization.
This retrieval-augmented approach:
Grounds model reasoning in domain-specific reference material
Reduces hallucinations by constraining generation to retrieved evidence
Improves consistency across similar clinical notes
Enhances transparency by persisting retrieved context alongside model outputs
Retrieved reference snippets are logged together with model inputs and outputs, enabling
clinician review, auditability, and retrospective analysis of how specific risk assessments
were generated.
🛠️ Design Principles
Human-in-the-loop: All outputs reviewed by clinicians
Security: Secrets Manager protects OpenAI API keys
Traceability: Logs and outputs saved to S3 for auditing
🧰 Technologies & Stack
Language & Orchestration: Python (CLI entrypoint, LangChain-based orchestration for sequential prompts + retrieval-augmented generation)
Retrieval-backed risk assessment and summaries with persisted reference snippets to support clinician review and auditability
Configurable risk thresholds and clinician-level filters (e.g., by physician ID and date range)
Automated SES email alerts with structured summaries for flagged high-risk patients
End-to-end logging of model inputs/outputs to S3 for auditing and reproducibility
🛡 Safeguards & Failure Handling
All model inputs and outputs are logged to S3 and are fully traceable
Hallucinations are mitigated by constrained output formats and schema-style extraction
Risk alerts require confidence / risk thresholds before being sent
No model outputs are sent directly to patients at any point
All alerts are routed only to licensed clinicians for review and decision-making
Graceful failure handling with conservative defaults if retrieval, parsing, or scoring fails
⚠️ Limitations & Responsible Use
This project is intended as a demonstration of how large language models can help prioritize clinical review
workloads. It is not a diagnostic tool and does not independently determine care plans or patient outcomes.
All outputs must be interpreted by licensed clinicians familiar with the patient’s history and context.
Model outputs may reflect biases or gaps present in the underlying training data
Clinical notes vary widely in quality and structure, which may impact model performance
LLM-generated text can include mistakes or omissions, even when sounding confident
Risk scores are decision-support heuristics, not clinical predictions or guarantees
The system has not been validated against real-world health outcomes data
Accordingly, this system is designed with a human-in-the-loop by default: it prioritizes cases for clinician
review but does not replace clinical judgment, and no model outputs are ever sent directly to patients.
🧪 Evaluation & Validation Approach
Because this system is designed as decision-support rather than a diagnostic tool, evaluation focuses on
workflow impact and usability rather than clinical outcome prediction. Validation to date has emphasized:
Face validity: clinician-style review of outputs for plausibility and clinical coherence
Content validity: checking whether key risk factors mentioned in notes appear in the model summaries
Stability testing: ensuring similar notes receive similar scores and recommendations
Error analysis: manual review of false positives and false negatives to refine prompts and thresholds
Threshold tuning: adjusting risk cutoffs to balance sensitivity vs. alert fatigue
A lightweight internal test set of patient-note examples was used to iterate on prompts and thresholds. Future
extensions may include blinded clinician comparison studies, inter-rater agreement metrics, and validation
against structured outcomes when appropriate approvals and de-identification procedures are in place.
🔍 LLM Prompt Design & Review Workflow
A general RISEN framework (Role, Input, Steps, Expectation, and Narrowing) was used to guide the formulation of the different
sequential prompts used across the workflow. Different prompts performed different roles (e.g., an initial prompt identifying
high-risk patients, and a secondary prompt summarizing/making recommendations for each high-risk patient).
During development, these different prompts were updated in an iterative process until they delivered consistent results for
their desired purpose. Please find an example of the initial risk-assessment prompt listed below:
Please assume the role of a primary care physician. Based on the following patient summary text,
provide a single risk rating between 1 and 100 for the patient's need for follow-up care within the next year,
with 1 being minimal risk and 100 being the greatest risk.
Respond in the following format:
Risk Score: <numeric_value>
<Brief explanation or justification here (optional)>
Here is the patient summary:
This Agentic Workflow deploys a sequential combination of multiple LLM prompts, NLP/regex applications, and numeric
calculations to provide the desired analysis.
The workflow is described as agentic because multiple prompts operate in sequence, with the
output of one step guiding the next. Rather than a single call to an LLM, the system performs staged reasoning:
it first detects whether a note includes potential high-risk findings, then assigns a numeric risk score, then
generates a human-readable clinical summary, and finally recommends potential follow-up actions for clinician
review.
🔔 Why This Matters
Clinicians face an overwhelming volume of unstructured documentation, and published estimates suggest a substantial
share of clinician time is spent on paperwork and documentation review. Much of this time is consumed by
manual triage of free-text notes to determine which patients require follow-up attention.
This pipeline is designed to reduce that burden while keeping clinicians fully in the loop:
Processes a typical patient note in ≈ 3 seconds
Replaces manual reviews that often require 3–5 minutes per note
Represents a >95% reduction in time spent per flagged case
Surfaces high-risk patients who might otherwise be missed in large populations
Returns structured, clinician-readable summaries rather than raw model output
The result is not automation of medical decision-making, but meaningful reallocation of clinician time —
less time searching through notes, more time engaging directly with patients.
🚀 Future Directions
Interactive web-based review portal: enable clinicians to view flags, modify scores, and provide feedback directly
Clinician-scored benchmarking study: compare model scores and summaries with independent clinician ratings of the same notes to establish agreement levels and identify failure modes
Domain-adapted or fine-tuned clinical LLMs (where appropriate approvals and data governance allow) explore domain-specific models trained on de-identified clinical text to improve stability and recall of clinically relevant findings
Multi-modal input support: expand beyond text to incorporate labs, structured fields, and imaging reports for richer risk assessment
Together, these extensions would support more rigorous validation, enable continuous model improvement through clinician feedback,
and move the system closer to real-world deployment while maintaining strong human oversight.
📊 Example of Application Input/Output
Input Patient Note
A 59-year-old male patient with chronic alcoholism and hepatitis B virus carrier was diagnosed with alcoholic liver cirrhosis and hepatocellular carcinoma (HCC) two years ago. Then, he received transcatheter arterial chemoembolization therapy three times and has been living without recurrence. The patient visited our emergency department with the symptoms of headache beginning 10 days prior and progressive left hemiparesis, altered mentality occurring two days prior. He was afebrile and his vital signs were stable. There were no leukocytosis and C-reactive protein (CRP) was 4.04 mg/L of blood. Upon a neurological examination, he was drowsy with disorientation and revealed decreased upper and lower extremities motor power to grade IV. DWI of the brain was performed because of suspicion of cerebral infarction. It showed a multi-lobulated cystic mass lesion and associated mild edema located in the right parieto-occipital lobe. We considered the possibility of a metastatic brain tumor at the first impression owing to negative diffusion restriction sign and a history of HCC. Contrast enhanced MRI combined with DWI revealed a multi-lobulated cystic rim-enhancing mass with surrounding edema and hypointensity in the cystic cavity on the DWI. Stereotactic biopsy with aspiration was performed on the assumption of HCC multiple metastasis in the brain and the result revealed BA involving multiple bacterial colonies. However, because the bacteria was not cultured, an initial antimicrobial therapy was started on the basis of the standard empirical treatment that consists of vancomycin plus a third-generation cephalosporin and metronidazole. Despite the use of the above antimicrobial therapy, clinical deterioration with an increasing abscess size on cranial imaging made further stereotactic aspiration and cultures including fungus, parasite and tuberculosis mycobacterium. The amount of vancomycin dosage was increased in order to increase the CSF concentration of vancomycin but intermittent spiking fever continued and patient's clinical symptoms did not improve. Even though there were no bacterial growth in the cultures, considering the situation that antimicrobial-resistant gram-positive strains is increased, we had to change the previous antibiotics to line.
Note: Retrieved clinical reference snippets used during risk assessment are persisted
alongside model inputs and outputs in S3 for audit and review, but are not included
verbatim in clinician-facing emails to avoid unnecessary cognitive load.
Output Email Body (Sent to patient's clinician)
Hello Team,
Please review the following high-risk patient notes and follow-up recommendations
from 2024-05-01 to 2024-05-07:
📋 Patient ID: 129848
Visit Date: 2024-05-04 00:00:00
Risk Score: 95 (1–100 scale)
Follow-up 1 Month: Yes
Follow-up 6 Months: Not mentioned
Oncology Recommended: Yes
Cardiology Recommended: Not mentioned
Top Medical Concerns:
1. Brain abscess and bacterial infection
2. Management of hepatocellular carcinoma and liver cirrhosis
3. Antimicrobial therapy and antibiotic resistance
4. Neurological symptoms and motor deficits
5. Cerebral edema and mass lesion in the brain
----------------------------------------
Regards,
Your Clinical Risk Bot